Hi @Zelldon
Hope you are doing good.
Looks like I have posted a lot of messages thus things are getting messed up, Sorry for that.
So after changing configuration to 5 nodes and increasing management thread to 5 we were unable to connect to our zeebe broker but then when we reverted the management thread to 1 it was all fine.
You can refer to the comments above where I have listed all the Scenarios which we have uncovered with our load.
To be specific see
-
Zeebe Low Performance (Configuration Type 1)
-
Zeebe Low Performance (Configuration Type 2)
All the configuration details are within the comment section.
Question 1
After you change the configuration to 5 nodes you mentioned dealine exceeded. How often do you see this? Do you use then a standalone gateway?
Yes till when we changed the management thread to 1 it was always there.
We are using standalone gateway with 3 replicas.
Question 2
It would help to understand the setup better if you always share your complete configuration, e.g. the values file, the helm version etc.
zeebe-cluster:
clusterSize: "5"
partitionCount: "16"
replicationFactor: "3"
cpuThreadCount: "4"
ioThreadCount: "4"
global:
logLevel: debug
gateway:
replicas: 3
logLevel: debug
prometheus:
servicemonitor:
enabled: true
# tolerations:
tolerations:
- effect: NoExecute
key: role
operator: Equal
value: zeebe
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- zeebe
# JavaOpts:
# DEFAULTS
JavaOpts: |
-XX:+UseParallelGC
-XX:MinHeapFreeRatio=5
-XX:MaxHeapFreeRatio=10
-XX:MaxRAMPercentage=25.0
-XX:GCTimeRatio=4
-XX:AdaptiveSizePolicyWeight=90
-XX:+PrintFlagsFinal
-Xmx4g
-Xms4g
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/usr/local/zeebe/data
-XX:ErrorFile=/usr/local/zeebe/data/zeebe_error%p.log
# RESOURCES
resources:
limits:
cpu: 5
memory: 12Gi
requests:
cpu: 5
memory: 12Gi
# PVC
pvcAccessMode: ["ReadWriteOnce"]
pvcSize: 128Gi
# ELASTIC
elasticsearch:
replicas: 3
minimumMasterNodes: 2
service:
transportPortName: tcp-transport
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 100Gi
esJavaOpts: "-Xmx4g -Xms4g"
# tolerations:
tolerations:
- effect: NoExecute
key: role
operator: Equal
value: elasticsearch
resources:
requests:
cpu: 3
memory: 8Gi
limits:
cpu: 3
memory: 8Gi
Question 3
I revisited the previous posts and saw that you mentioned you are starting workflow instances via messages is this still the case? Are you using always the same correlationKey ? If you use always the same correlationKey then it will be published on the same partition.
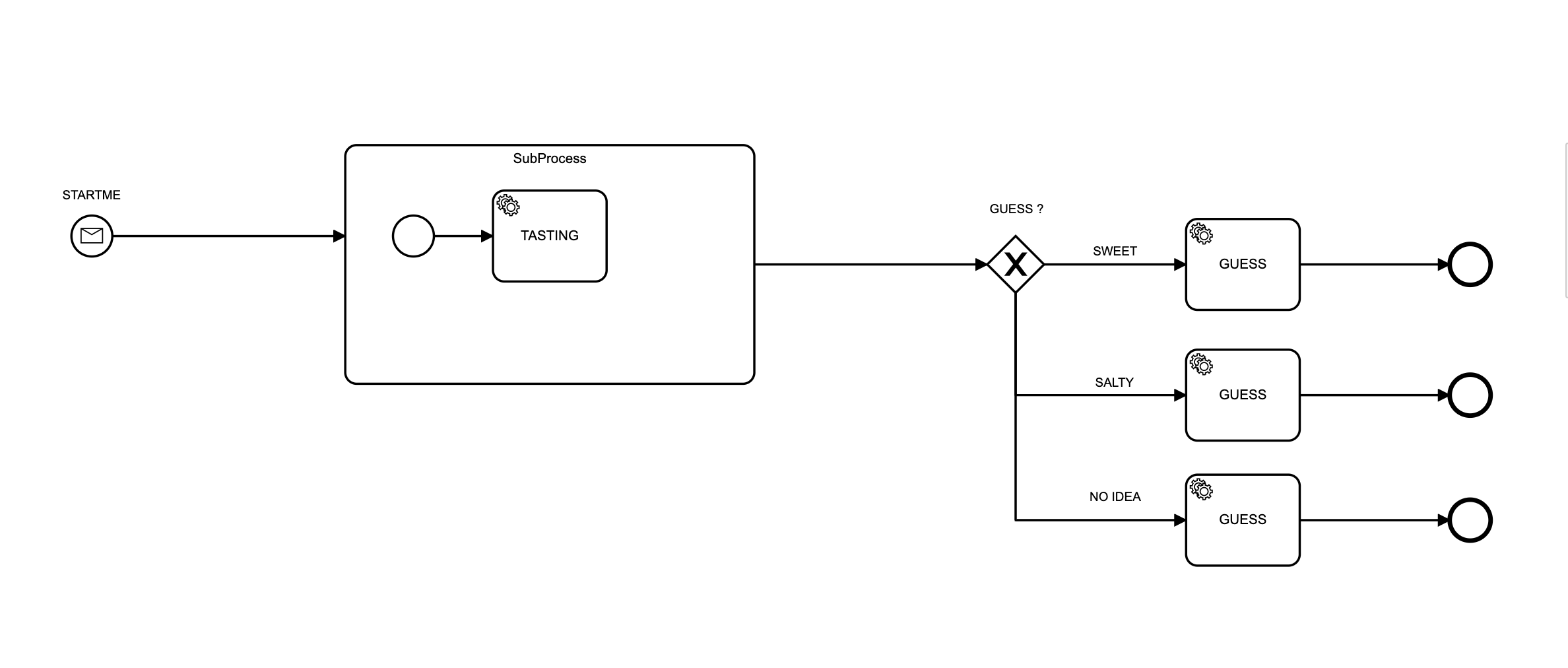
Yes we are using message start event to start our workflow
correlationKey is unique for a particular instance been started (that is our use case and we can’t devoid)
As I said correlationKey is unique for a particular instance and correlationKey is different for different instance.
Question 4
The job workers have 8 threads, but only 32 max jobs activate is this the case? Maybe you can increase the number as well.
The above configuration was default but we updated the configuration on the worker side as
@ZeebeWorker(`type` = "tasting", name = "tasting", maxJobsActive = 200)
with maxJobsActive as 200
Question 5
In you scenario descriptions what do you mean with “request processed = 20454 (Camunda operate)”*
You see that many instances in operate?
Grafana provides a graph for metrics result for total_number_of_requests been fired in Zeebe.
Ideally these request should be equal to the number of instance creation request I am sending from service but when we verified that the number was vague in a way it gives us more number of requests than actually fired.
Thus as a fallback we verified total number of instances completed on Operate which was genuine and we have noted down instances completed from the Operate data itself not the grafana metrics.
Bottom Line
We wanted to achieve a result of 1000 instance created / completed per seconds. Please let us know whatever configuration is required to achieve this number. We can even share you with the benchmark results but if someone can actively support us then we would really appreciate that since we have limited time now.