@Zelldon @jwulf hi guys
I have also consulted performance related issues before, this time I did a comprehensive test
1.Basic Information
(1) testing process:start->test task(type:test)->end
(2) zeebe server configuration: 4-core cpu 8G memory
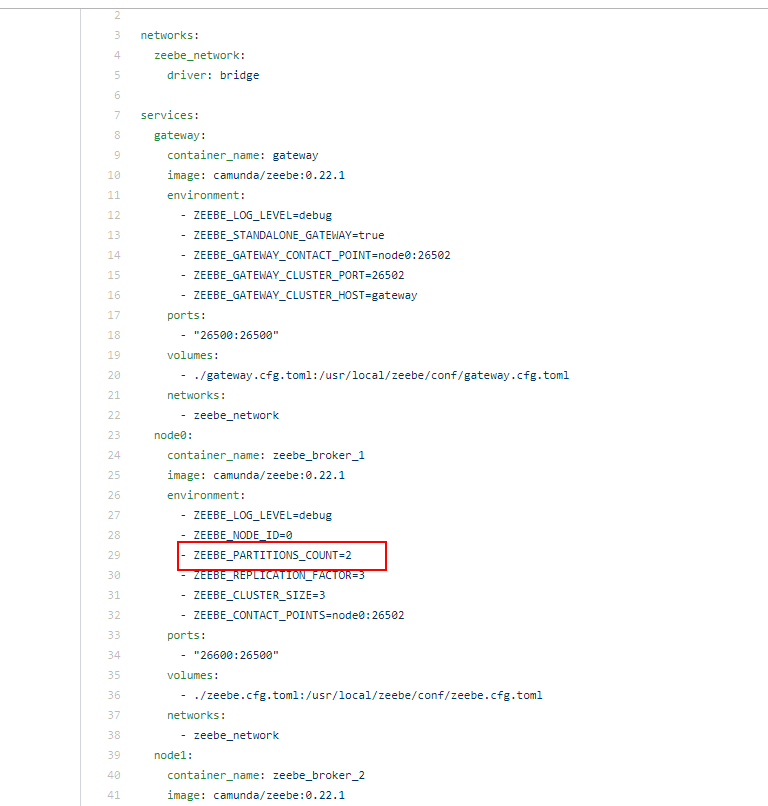
2.Use docker-compose to deploy files under the broker-only folder.
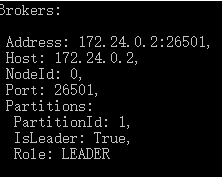
The topology result:
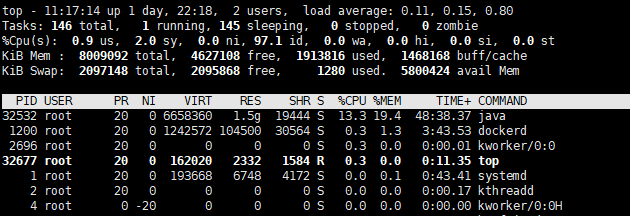
Use the command top to view server resource usage:
The microservice interface calls this test process by ZeebeClient:
var client = ZeebeClient.Builder().UseGatewayAddress(address).UsePlainText().Build(); var result = await client.NewCreateWorkflowInstanceCommand().BpmnProcessId("test-perf").LatestVersion().Send();
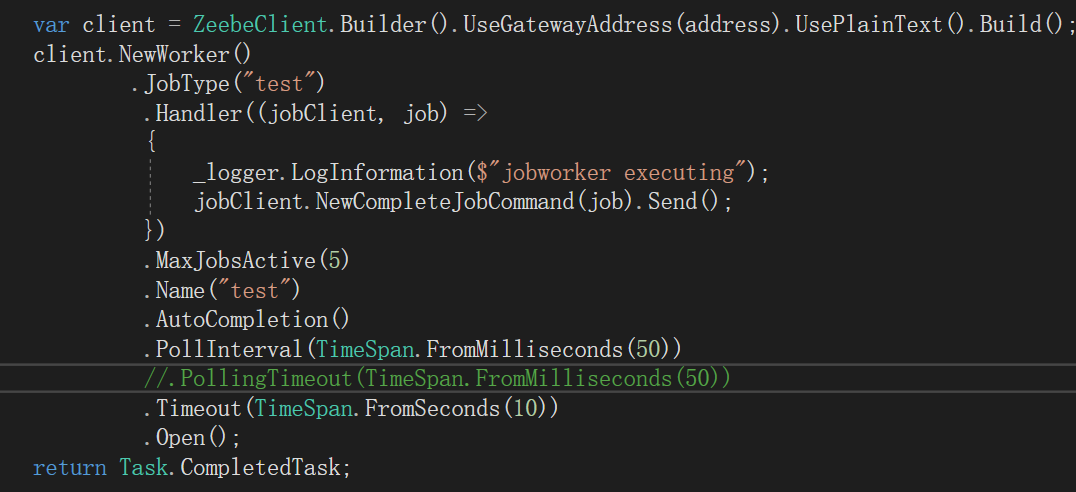
The JobWorker code:
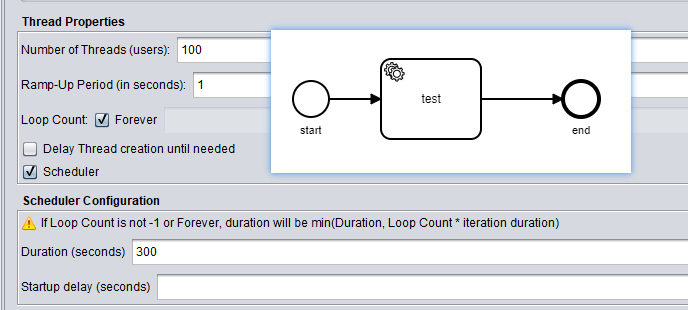
3.Testing with Jemter tools:
(1) 50 calls per second

(2) 100 calls per second
and modify the configuration items of the Jobworker: MaxJobActive由5变成15,PollInterval由50ms变成10ms
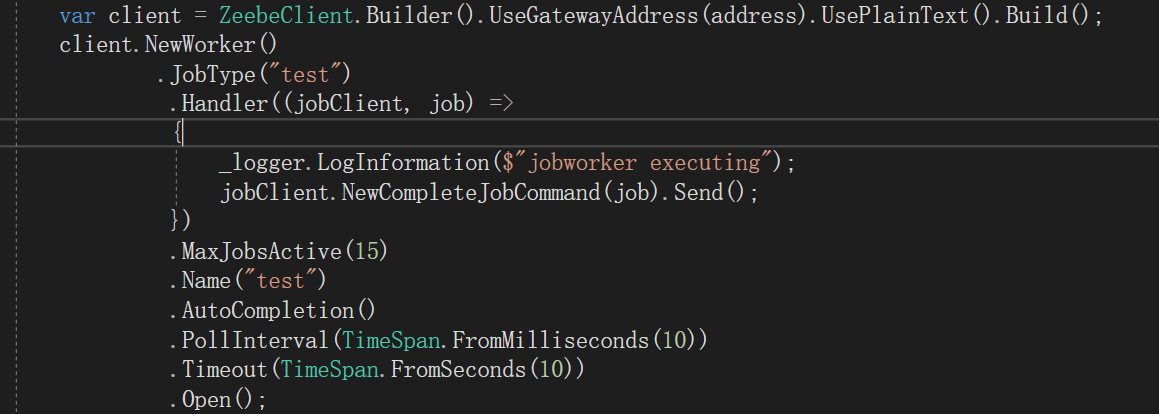
However, throughput has not improved. I started two JobWorkers, the code of both is exactly the same, they are two independent processes. Using 2 JobWorkers to consume messages, the effect remains the same.

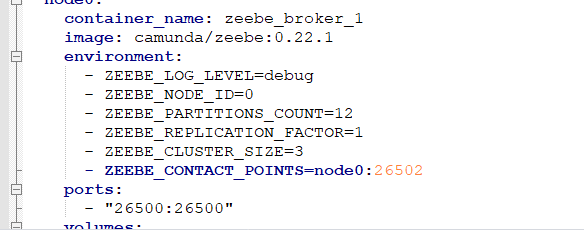
4.Using multiple JobWorkers
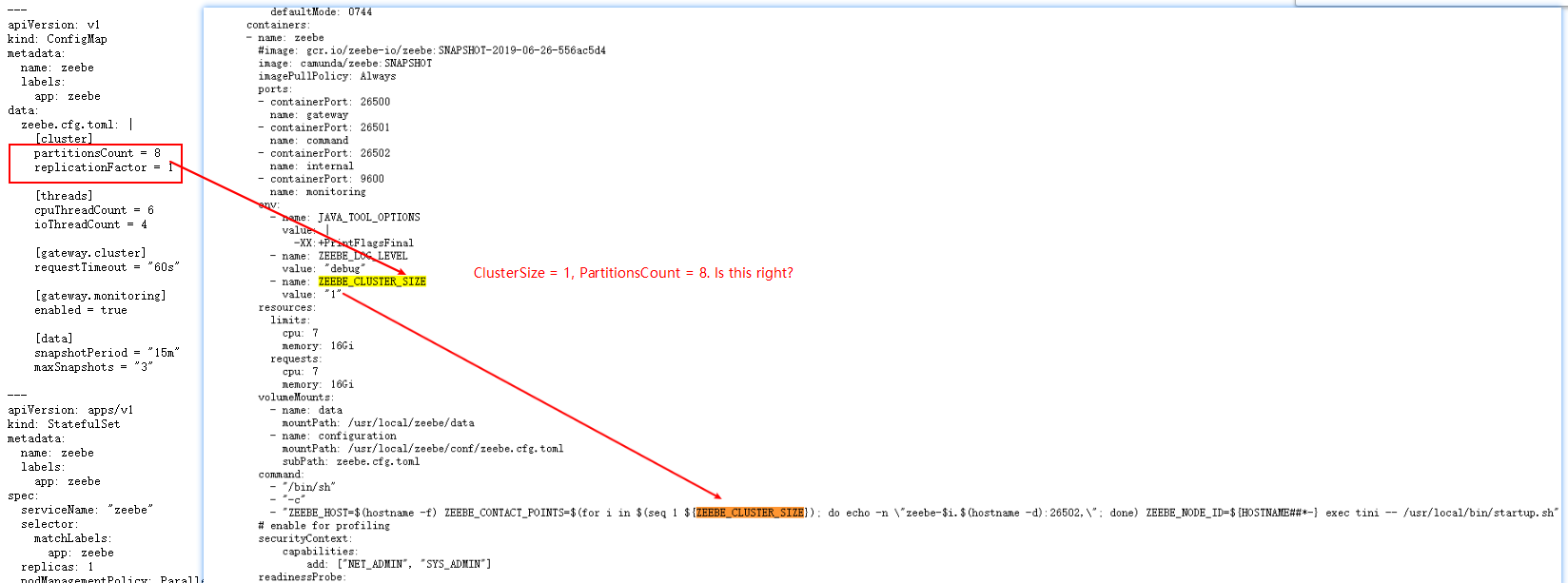
I found that starting multiple JobWorkers did not improve throughput, so I redeployed the zeebe brokers on the server and used the standalone-gateway file to download the file.
After the deployment is completed, it is found that the server resources are increased.
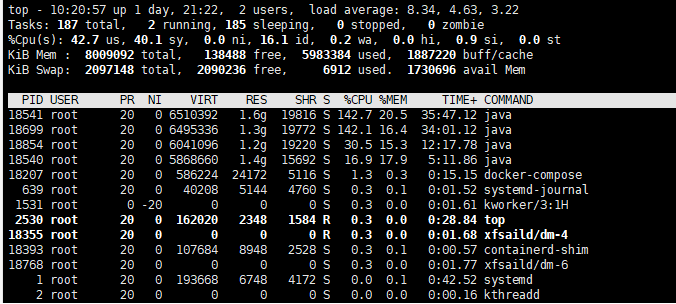
Then repeat the above operation:
When called 50 times per second, Jmeter results show high error rate:19.62%, we cannot accept this error rate.
5. Use two processes, but the same type of ServiceTask
I create two process files using Zeebe Modeler:
BpmnId: test-perf, Start-> Task (type = test)-> End
BpmnId: test-perf-v2, Start-> Task (type = test)-> End
These two processes were called using two microservice APIs, respectively, and eventually found that the threshold of throughput 40 was fixed, and the results of the two APIs were 20

After the above operations, I have a few questions:
- Is single node service better than cluster? Cluster is just distributed fault-tolerant?
- When I modify the configuration code of the JobWorker, I find that the throughput cannot be changed, that is, the modification of the JobWorker configuration cannot change the consumption speed? (Actually, I observed the consumption speed and found that there is a change. Using PollInterval = 50ms and PollInterval = 10ms, the consumption speed is different.)
- Why can’t I change the throughput by enabling multiple JobWorkers? Similar to MQ, if you increase the number of consumer services, you can increase throughput. Why can’t Zeebe?
At present, the concurrent support of a single node calls the microservice API 150 times per second. This result is acceptable. But the throughput is still too low.