After reading the blog entry for great success in the speed of your new platform, I decided to implement a PoC that would allow us to switch our classic workflow system to microservice architecture in the future with Zeebe (thanks to the Camunda developers for their great work and hope).
However, after several attempts to achieve at least close to the same indicators as you, the maximum that I have succeeded in is the speed of launching processes - 300 per second.
The server, your client code, or the machine (hardware/OS).
The obvious things to do are:
Run the client code from the benchmark against your docker server.
Run your client code against the server in the benchmark (was that dockerised?)
Run the exact benchmark as it was done on the same hardware. (Verify the results and that you can replicated them)
Run the benchmark as it was run on your hardware. (Get a baseline of your hardware)
Performance profiling like this is just basic science: Experimental design and observation, hypothesis generation and invalidation.
My hypotheses about your experimental design are these:
You have degradation due to dockerisation.
Dockerised server is resource starved.
Running server in docker is slower than native (if your OS is not the same as the benchmark / the benchmark was run on a non-dockerised server)
Your client code cannot generate the same input as the benchmark code.
Your resources do not match the benchmark resources.
The four experimental combinations that I recommended above are sufficient to differentially invalidate or strengthen these hypotheses, and provide input for generating new hypotheses - or direct your attention to the part of the system where you need to experiment further to refine a hypothesis.
For example: if the benchmark client is faster than your Go client against the same server, then you would develop a hypothesis about your client code. Is it blocking? What happens if you run two instances of it in parallel?
Etc…
There is no silver bullet configuration. You have to experimentally (in)validate your hypotheses and do exhaustive testing.
That was the point I was trying to make in that performance profiling blog post.
You should run a bunch of combinations and come up with a hypothesis with proof, like: “I think that the Go client has an issue where it can’t generate requests as fast as the Java client because I have these three experiments that show these results…”
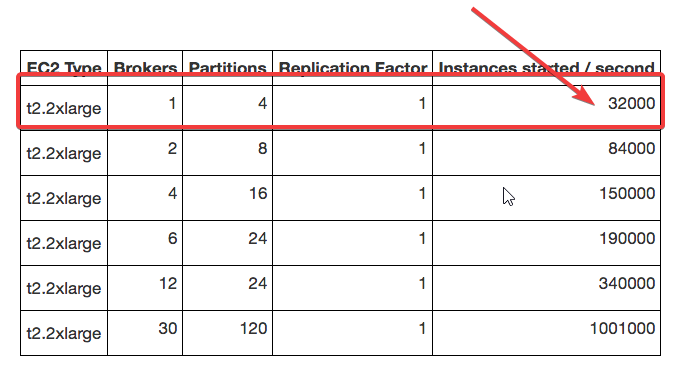
And so, after several days of testing i was not able to achieve the declared speed. Just to understand, I focus on this indicator.
Next I will write the test parameters:
We started testing with docker-compose and broker-only, with default settings. Speed was about 100 instance per second. When increasing the speed of the client (add worker number on Go application), the broker began to return an error: “Reached maximum capacity of requests handled”
Further, partitions were gradually increased, until server resources ceased to be enough, we achieved a speed of 300+ per second.
After that we started the broker directly, from the distribution Release Zeebe 0.20.0 and Operate 1.0.0 · camunda/zeebe · GitHub (without docker). As in the previous case, the partitions and the speed of sending requests by the client were increased, as long as there were enough resources. Speed reached a little less than 400 per second.
So we still didn’t understand what needs to be changed so that the difference between the declared speed and our indicators would be at least not 100 times.