Xu Cao: Hi, I was testing out zeebe’s timeout error handling. so I set a sleep time inside the task longer than what’s been set on the task function’s timeout parameter. But it doesn’t seem to throw the timeout exception and exit the workflow with the exception error. anyone experienced this and what the resolution to it? in my main.py the task function is as following:
def process(**kwargs):
print("Processing stuff...")
time.sleep(600)
return {"output": {"results": kwargs["input"]["stuff"]}}
Josh Wulf: Mmmmm….
So:
The timeout resolution in the broker is up to 30 seconds. It has like a “timeout sweeper” that runs on a 30 second interval. There is an open issue to make it more fine-grained.
When your job times out on the broker, it will be made available to be reactivated by another worker. Your worker will not throw - unless the library author made it do that.
If the rescheduled job is picked up by another worker, and the first worker completes it after the timeout, but before the second worker completes it, then it will be completed. The two workers who have both activated it are in a race to complete.
The first worker cannot fail the job after its timeout, but it can complete.
When whichever worker comes in second with the completion tries to complete it, it will receive an error response from the broker: “Job X not found”
Xu Cao: Thank you @Josh Wulf for a quick response! hmmm but that’s what I expected it to function. We have long running jobs so the task might be a prerequisite for other tasks to continue processing. So what we want or expect if this task is timed out, throw timeout exception and exit the workflow cause there is no point to going further if this task failed b/c of time out. I think it’s very valid normal use case. Does it make sense to you?
Josh Wulf: Put the whole thing in a sub-process, and put a boundary interrupt timer on that. This allows you to specify an overall process timeout: “OK, this whole thing took too long”
Josh Wulf: Like this:
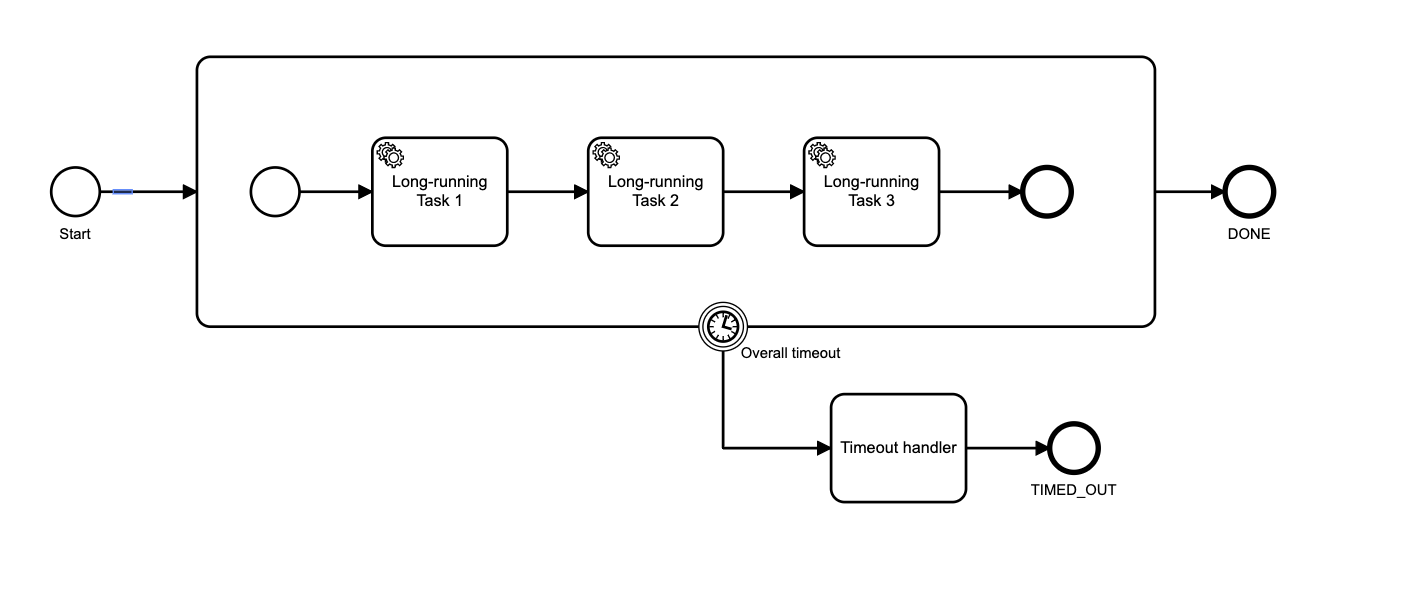
Josh Wulf: Is that what you are after?
Xu Cao: sort of. here is my workflow:
Josh Wulf: You could also do it per-task:
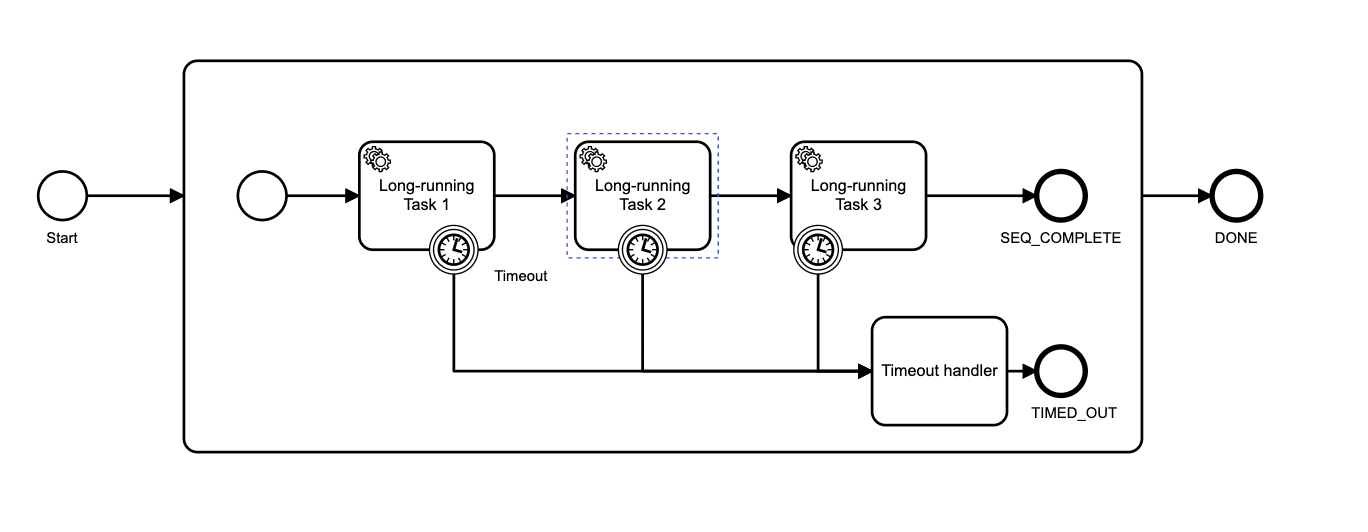
Xu Cao: notice the prepare variant task? it’s the prerequisite for all the following tasks in parallel. so I think I could try your idea to wrap that task with an interrupt timer boundary and see if it throws timeout error and exit the whole flow
Xu Cao: thanks for the idea. will try out. I’m brand new in zeebe. do you have a sample code somewhere to create a sub-process and add a timer to it?
Josh Wulf: That’s it
Josh Wulf: There is no code
Josh Wulf: I’m not sure on the timer resolution - it may have the same issue as the job activation timeout.
Xu Cao: I see. so I just use the modeler to do that?
Josh Wulf: Yes, exactly
Josh Wulf: What time duration are you looking at for the first task?
Xu Cao: it could be a bug as well: https://github.com/JonatanMartens/pyzeebe/issues/80
Xu Cao: I don’t know yet. we still defining the requirement. it could be under 1 min or a few min or hours or even weeks
Xu Cao: we are POC with zeebe and prototyping our new workflow system
Josh Wulf: I think you want the timer interrupt
Xu Cao: got it. will try it out. Thanks Josh!
Josh Wulf: The job activation is a contract between a worker and the broker for a single unit of work, a job. If the worker fails, then the broker doesn’t hear back from it - and when that contracted time expires, the broker makes the job available to any other worker that is asking for jobs.
When you want to kill the entire process when a unit of work is not completed in time, then a timer interrupt to an end event will do it.
One thing to note: this makes your worker failure invisible. If the workflow is failing because all the workers are dead, modelling it like this will just make all your workflows time out and end, whereas setting retries to 1 for that task will cause the workflow to raise an incident if it is not completed in time.
With a timeout handler, you can raise some kind of custom notification via that worker (like Slack or Pushover) - and if that task times out, then an incident will be raised when it runs out of retries.
Note: This post was generated by Slack Archivist from a conversation in the Zeebe Slack, a source of valuable discussions on Zeebe (get an invite). Someone in the Slack thought this was worth sharing!
If this post answered a question for you, hit the Like button - we use that to assess which posts to put into docs.